

One of the most salient features of our culture today is that there is so much slop. Each of us has been subjected to this; each of us contributes their share. But what even is AI slop?
To investigate this, I:
- Conducted qualitative and quantitative analyses of sources referenced in the Wikipedia page on AI slop. From these, I construct four dimensions for slop: themes, types, qualities, and metaphors.
- Created the SlopNews dataset, used to analyse the statistical features of slop content. Compared to non-slop news, slop news is less complex, less varied, and has more positive sentiment.
- Created an archive (slopscooper) where I collect examples and publications about AI slop.
This is a synthesized version of my Master's dissertation. To read the whole thing, click here.
This is the third post of a series on AI slop. This part analyses the quantitative aspects of slop itself. The first post goes into the contextual information and theoretical aspects (history, philosophy, media theory) of slop, while the second one presents the results of the study on what people say about slop.
SlopNews
I introduce SlopNews, an English-language dataset containing 20,000 slop news articles, 20,000 human-written news articles, and 20,000 machine-generated news articles. The data are not shared directly due to copyright, but the dataset is easily reproducible.
This dataset focuses on “slop news” over other text-based slop (e.g., submission slop from e-books or academic papers) due to data availability. Ideally, the dataset would differentiate a) slop news from fake news, and b) high- from low-quality AI-generated content. However, these categories were not included in the dataset due to practical limitations.
The slop news sources were four websites identified by NewsGuard (Sadeghi & Arvanitis, 2023) and DoubleVerify (Luu, 2025). I scraped these. The non-slop news were sourced from these datasets:
- NeuralNews : human New York Times articles and AI-generated (GROVER) text (Tan et al., 2020);
- GlobalNews: Kaggle dataset obtained from NewsAPI (Saksham, 2023);
- NewsData.io: news data aggregation company which offers free small datasets;
Preprocessing and downsampling these gives us 20k of each category. You might notice that all the AI-generated articles are from GROVER, which is a major limitation of this study. The majority of slop content (~75%) comes form one website as well.
For some reason, the libraries (textdescriptives and flair) were not playing nice with the dataset, which in practice meant I could not use the AI-generated articles in the analysis. Most importantly, this also blocked the perplexity measure, which is the most important metric in AI detection. Since I was pressed for time, I just did it. I would implement my own text descriptives in the future to avoid this.
I analysed all kinds of metrics, including sentence length, token length, vocabulary size, stop word usage, readability (flesch reading ease), complexity (dependency distance), coherence (cosine similarity), polarity (textblob naive bayes classifier), subjectivity (same) and, most importantly, sentiment (using flair, a deep learning classifier). Since the purpose of science is to create tables (see Laboratory Life), here is a big table to convince you I am a real scientist:
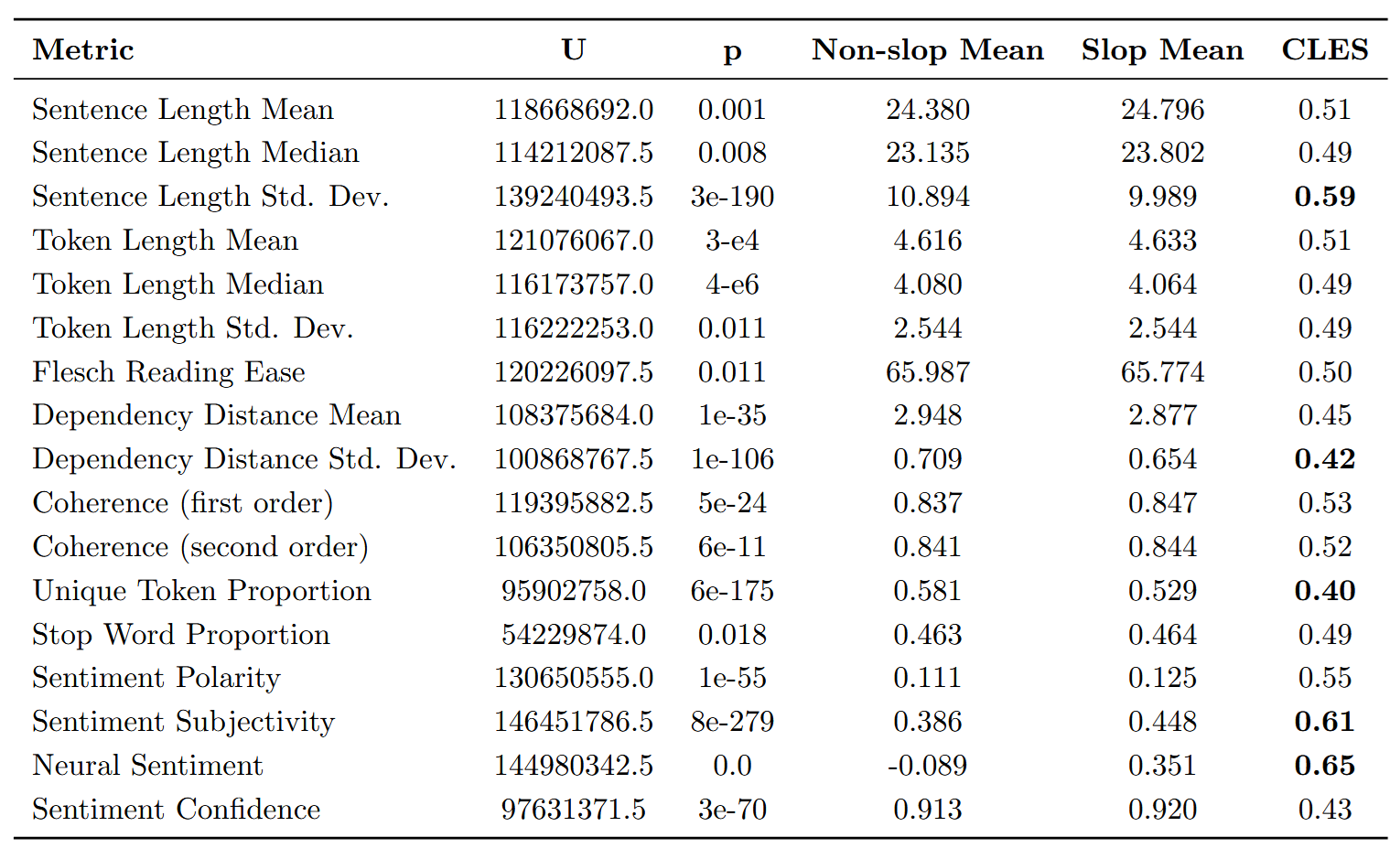
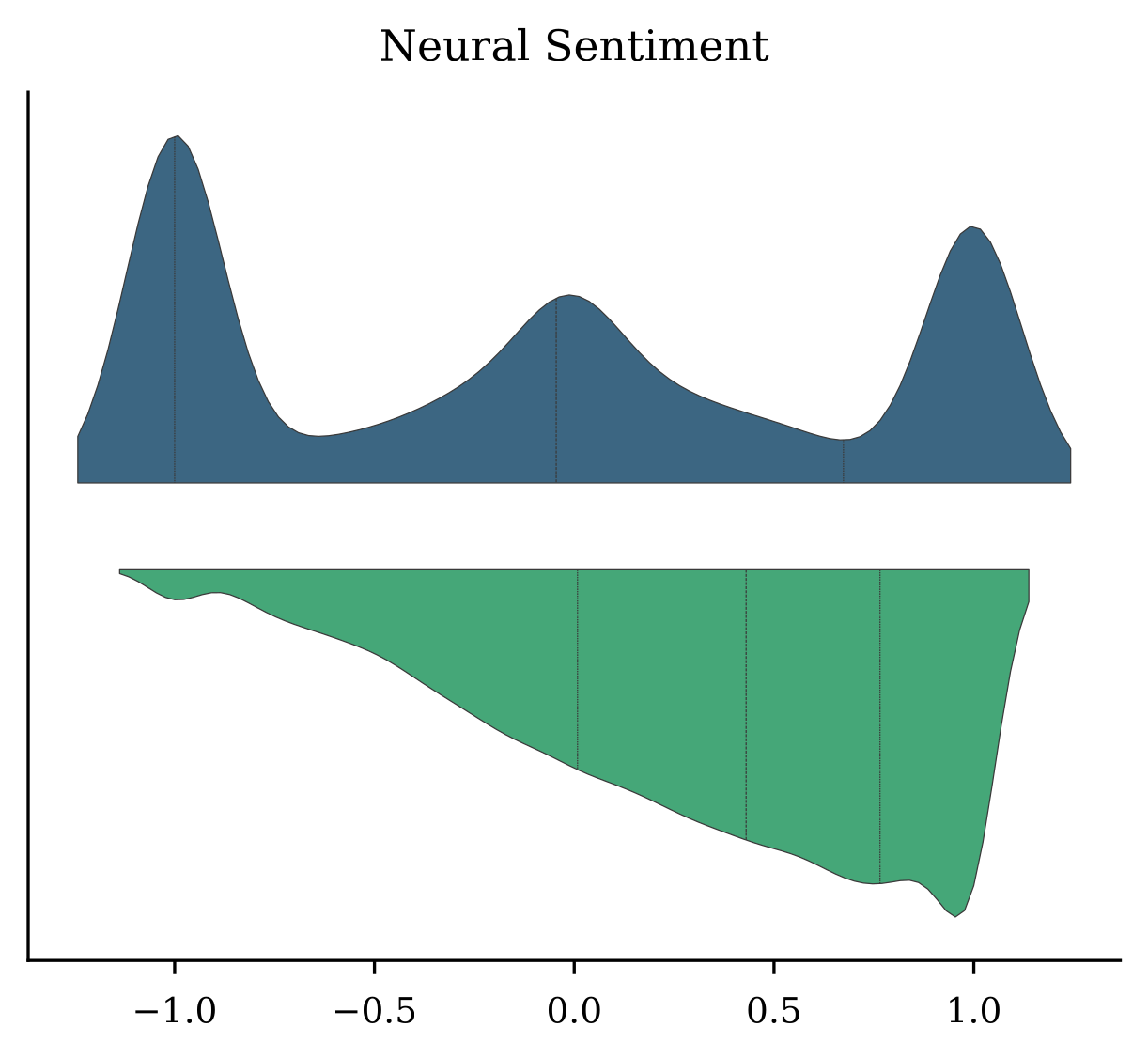
Statistical comparisons were conducted using two-sided Mann-Whitney U tests, and practical implications were considered by using the Common Language Effect Size (CLES). The most important results is as follows: neural sentiment for slop is concentrated around positive sentiment, whereas the non-slop distribution has three peaks around negative, neutral, and positive sentiment.
The literature shows that AI text tends to be more uniform than human-written text (Chen & Shu, 2024), which also seems to be the case here. Slop text has lower variation and complexity than non-slop text.
Slop articles also show higher sentiment scores in both simple (CLES 0.55) and neural (CLES 0.65) models, as well as greater subjectivity (CLES 0.61). These findings suggest that slop tends to exhibit more positive sentiment and subjectivity than non-slop. One possible explanation is that slop news aims to be unobtrusive, adopting a generic positivity. This contrasts with other kinds of slop, such as social media slop and disinformation, where the purpose is being attention-grabbing.
These differences are modest but measurable. Of the features investigated, lexical diversity, dependency structure, and sentiment offer the most promise for slop classification. The most noticeable difference occurs in the distribution of sentiment across slop and non-slop, as there are almost no slop news articles with negative sentiment.
Limitations and Future Work
A wider range of linguistic metrics could be considered here, such as:
- Known slop fingerprints: accidental prompt disclosure, model refusals, vocabulary patterns, emoji usage, and markup features. Sources include the Wikipedia Project AI Cleanup, Problematic Paper Screener, originality.ai blog, and Pangram Resources for Educators.
- Valence, arousal, and dominance (VAD) metrics (Mohammad, 2025; Vishnubhotla & Mohammad, 2022)
- Linguistic Inquiry and Word Count (LIWC) features
- Givenness as a measure of complexity
- Type Token Ratios (TTR) as a measure of lexical diversity
It is important to emphasize that the statistical findings presented here are unlikely to be generalizable. The observed differences are relatively weak and likely reflect biases (e.g., stylistic traits) in the data source selection rather than differences intrinsic to the slop/non-slop distinction. Some distributional differences exist between slop and non-slop text, but they are not robust enough to support reliable classification or decision-making on their own.
Much like misinformation, AI slop is primarily image-based. This study deliberately focuses on text, which is not necessarily representative of wider slop trends. Though this is particularly useful for people in fields in which text is the main component, such as information reliability, social media moderation and scientific integrity.
This study is, to the best of my knowledge, the first systematic analysis of AI slop. Although limited, it outlines potential directions for further research and lays the groundwork for developing interpretable systems for slop detection. By advancing our understanding of AI slop, this work aims to support efforts to safeguard the integrity of the information environment.
If you would like to be notified whenever I release more stuff like this, sign up here.